Benutzer-Werkzeuge
Importieren und Exportieren
⯇ Zurück zu Menüs und Werkzeuge Wasserversorgung
⯇ Zurück zu Menüs und Werkzeuge Siedlungsentwässerung
Menüpunkt: Werkzeuge > Importieren und Exportieren
Handbuch: MIKE+ Model Manager User Guide (page 137) • section 6 Import and Export
Inhaltsverzeichnis
Einleitung
Bevor Sie weiterlesen, möchten wir auf das kostenlose On-Demand Webinar Import und Export in MIKE URBAN+ aufmerksam machen. Die Aufzeichnung ist zwar nicht mehr ganz taufrisch, aber in den Grundzügen immer noch gültig.
Erhalten Sie eine kurze Einführung in unserem kostenlosen
On-Demand Webinar Import und Export in MIKE URBAN+
Der Import von Netzdaten in MIKE+ funktioniert über die Import-Export Schnittstelle. Diese Schnittstelle bietet Ihnen die Möglichkeit mit Hilfe einer Benutzeroberfläche die notwendigen Zuordnungen zwischen Quelldateien verschiedener Datentypen und den Zieltabellen in MIKE+ vorzunehmen. Die aktuelle Seite erklärt generell die Import-Export Schnittstelle.
Ergänzend finden Sie auf…
…Setups zu konkreten Datenformaten, sowohl für den Import, als auch den Export.
Das Import/Export-Werkzeug ist in zwei Arbeitsflächen unterteilt: Im linken Teil wird allgemein die Importaufgabe festgelegt, während sie im rechten genauer definiert werden kann. Eine Aufgabe (im linken Teil) kann aus mehreren Konfigurationen (im rechten Teil) bestehen, die sich normalerweise auf eine Tabelle oder Feature Class beziehen. Die Konfiguration wiederum wird in mehrere Zuweisungen unterteilt, die sich auf die einzelnen Spalten einer Datei beziehen.
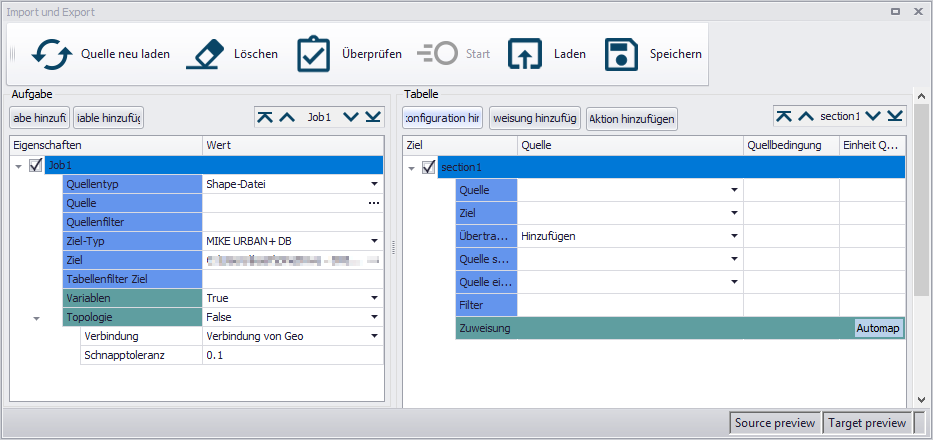
Wenn Sie Daten nach MIKE+ importieren möchten, wird der externe Datensatz als "Quelle" angegeben, während das "Ziel" die MIKE+ Datenbank ist, in der Sie gerade arbeiten. (Wenn Sie einen Datensatz exportieren möchten, müssen Sie natürlich genau umgekehrt vorgehen.)
Werkzeugleiste
Diese Werkzeugleiste brauchen Sie in der Regel erst, nachdem Sie Aufgaben und Tabellenkonfiguraton erstellt haben. Überspringen Sie diesen Abschnitt, wenn Sie möchten.

| Werkzeug | Erklärung |
|---|---|
| Quelle neu laden | Muss verwendet werden, wenn die Quelle noch einmal bearbeitet wurde |
| Löschen | Löscht die gesamte Import-Konfiguration |
| Überprüfen | Bevor der Import durchgeführt werden kann, muss er auf Fehler überprüft werden. |
| Start | Nach dem Überprüfen können Sie den Import starten. |
| Laden | Lädt eine gespeicherte Import-Konfiguration 1) |
| Speichern | Speichert die aktuelle Import-Konfigurationen als xml-Datei für eine spätere Verwendung |
Aufgabe
Klicken Sie auf "Aufgabe hinzufügen" um mit dem Aufbau der Importschnittstelle zu beginnen. Den Namen der Aufgabe (Standard: Job 1) können Sie mit einem Doppelklick bearbeiten. Folgend werden die einzelnen Dialogfelder der Aufgabe erklärt.
| Parameter | Erklärung |
|---|---|
| Quellentyp | Datenformat, aus dem importiert werden soll; Details siehe unten "Quellentyp beim Import" |
| Quelle | Mit einem Klick auf "…" können Sie den Ordner auswählen, in dem sich Ihre Quelldatei befindet. |
| Quellenfilter | Hier können Sie Filter in Form eines Texts eintragen, um nur bestimmte Quelltabellen anzuzeigen. Wenn Sie beispielsweise ein MU Classic Projekt importieren möchten, können Sie "msm*" (ohne Anführungszeichen) eintragen, um alle Tabellen anzuzeigen, die mit "msm" beginnen. |
| Zieltyp | Der Zieltyp wird spezifiziert, wobei die gleichen Datentypen zur Verfügung stehen, wie beim Quellentyp. Wenn Sie eine neue Aufgabe erstellen, wird automatisch zur aktuellen MU+ Datenbank verbunden. |
| Ziel | Mit einem Klick auf "…" können Sie den Ordner auswählen, in dem sich Ihre Zieldatei befindet. |
| Tabellenfilter Ziel | Funktioniert gleich wie oben erklärter Quellenfilter |
| Variablen | Nicht relevant, wird später erklärt |
| Topologie | Es wird festgelegt wie die Topologie im Netz aufgebaut werden soll. Bei "True" wird der Von- und Nach Knoten in der "Link"-Tabelle befüllt. |
| Verbindung | Connection from Geo: Geometrie ist definiert, die Verbindung der Topologie nicht. (Es werden also die Spalten "Von Knoten" und "Nach Knoten" befüllt.) Geo from Connection: Die Netzverknüpfung ist definiert durch einen Wert für den "Von/Nach Knoten", die Geometrie wird nicht ausgelesen. |
| Schnapptoleranz | Zusätzlicher Parameter für "Connection from Geo". Definiert Suchradius für die Knoten und Haltungen die geschnappt werden sollen |
Quellentyp beim Import
| Quellentyp | Erweiterung | Kommentar |
|---|---|---|
| Shape-Datei | *.shp | Quelle kann eine einzelne Shape-Datei sein oder ein Verzeichnis mit mehreren mehreren Shape-Dateien. |
| Excel Datei | *.xlsx | |
| CAD Datei | *.dwg | Kann in Abhängigkeit der .dwg Struktur komplex sein. |
| Geodatenbank2) | *.gdb (File Geodatabase) *.mdb (Personal Geodatabase) | |
| ODBC – Microsoft Acces ODBC – SQLite | *.mdb *.sqlite | ODBC-Treiber müssen unabhängig von MIKE+ installiert werden. |
| ISYBAU XML | *.xml | ISYBAU Versionen 2006/2013/2017 getestet. |
| Ergebnis-Layer | *.res1d | |
| MIKE+ DB | *.mupp und *.sqlite | |
| SQL Server | ||
| Oracle Spatial |
Eine allgemeine SQLite-Datenbank wird noch nicht unterstützt, siehe Fall 1815 (intern).
Zieltyp beim Export
| Zieltyp | Erweiterung | Kommentar |
|---|---|---|
| Shape-Datei | siehe unten | |
| Excel Datei | ||
| Geodatenbank | siehe unten | |
| ODBC | ||
| ISYBAU Datei | ||
| MIKE URBAN + DB |
Details zu Shape-Datei
Wenn lediglich ein Verzeichnis angegeben wird, sind in den Tabellenkonfigurationen die Namen der Shape-Dateien erforderlich. Der Verzeichnispfad kann absolut (T:\meinArbeitsverzeichnis\shpexport) oder relativ (shpexport) angegeben werden.
Alternativ kann man als Ziel auch direkt eine ganz bestimmte Shape-Datei festlegen (shpexport\leitungen.shp), allerdings kann man dann in der Tabellenkonfiguration lediglich in diese eine Shape-Datei schreiben.
Details zu Geodatenbank
Erstellen Sie ein leeres Verzeichnis mit Endung gdb, damit MIKE+ das Ziel anerkennt. Das Koordinatenbezugssystem aus MIKE+ wird nicht übernommen, sondern auf WGS84 gesetzt.
Wenn Sie hingegen in ArcCatalog eine leere Geodatenbank erstellen, wird sie von MIKE+ als Ziel nicht akzeptiert mit der Fehlermeldung  ROBE.
ROBE.
Topologie
Mit "Topologie" steuern Sie, wie Knoten und Kanten miteinander verbunden werden. Wenn "Topologie" aktiviert ist, müssen Sie auch die Parameter "Verbindung" und "Schnappdistanz" beachten.
Falls Sie die Topologie nicht im Rahmen des Imports bereinigen, stehen im Menü "CS-Netzwerk > Netzbearbeitungswerkzeuge > Topologie bereinigen" Werkzeuge für die Nachbearbeitung zur Verfügung.
Verbindung
Wenn Sie aus GIS-Daten importieren, also Knoten und Kanten über Koordinaten verfügen, wählen Sie die Option Verbindung von Geo.
- Wenn sich innerhalb der Schapptoleranz ein Knoten findet, werden in den Kanten die Spalten "FromNode" und "ToNode" befüllt.
- Wenn sich innerhalb der Schnapptoleranz kein Knoten findet, wird ein neuer Knoten erzeugt, und die neue MUID in das entsprechende Feld "FromNode" oder "ToNode" eingetragen.
- Das Finden bzw. Erzeugen von Knoten funktioniert auch dann, wenn lediglich die Kanten importiert werden, und die Knoten im Modell bereits vorhanden sind.
- Bei "Verbindung von Geo" bleiben eventuelle Stützpunkte entlang der Kanten erhalten.
- Die Kantenenden werden eventuell leicht verschoben, wenn der Knoten nicht genau mit dem Kantenende zusammenfällt.
- Wenn eine seitliche Einmündung auf eine durchgehende Kante trifft, wird die durchgehende Kante nicht aufgebrochen. Die seitliche Einmündung endet mit einem Endknoten. Solche Stellen müssen in MIKE URBAN bereinigt werden. Suchen Sie nach Endknoten im Menü Karte > Auswahl > Sonderauswahl.
Wenn Sie aus tabellarischen Daten importieren, die über Spalten für den Von-Knoten und den Nach-Knoten verfügen, wählen Sie die Option Geo von Verbindung.
- Dabei werden die Kanten als gerade Strecken zwischen den Knoten erzeugt.
Schnapptoleranz
Bei der Option "Verbindung von Geo" sucht der Import an den Kantenenden nach Knoten. Die Schnapptoleranz gibt den Suchradius an. Die Kantenenden werden an den gefundenen Knoten verschoben.
Tabellenkonfiguration
Innerhalb der Konfigurationen werden die Zuweisungen festgelegt.
| Parameter | Erklärung |
|---|---|
| Quelle | Quelldatei innerhalb des links festgelegten Quell-Ordner. |
| Ziel | Zieltabelle |
| Übertragungsart | Siehe unten |
| Quelle sortieren | Reihenfolge der Daten kann von einer Spalte abhängig gemacht werden |
| Quelle eindeutig | Festlegen einer Spalte, die eindeutig sein soll. Wenn diese nicht eindeutig ist, wird immer nur das erste Element importiert |
| Filter | Verwendet werden SQL WHERE Filter, siehe untern. |
Übertragungsart
Die fünf Übertragungsarten werden anhand zweier schematischer Datensätze erklärt.
Die bereits vorhandenen Zieldaten3) sind blau dargestellt und bestehen aus drei Elementen. Sie tragen die Identifikationen 1, 2 und 3 und weisen die Attribute A, B und C auf. Beim Datensatz mit der ID = 3 sind die Attribute B und C leer, d.h. datenbanktechnisch NULL.
Die zu ergänzenden Quelldaten sind rot dargestellt und bestehen ebenfalls aus drei Elementen. Sie tragen die Identifikationen 2, 3 und 4 und weisen die Attribute A, B und C auf. Beim Datensatz mit der ID = 2 sind die Attribute B und C leer, d.h. datenbanktechnisch NULL.
Hinzufügen
Bereits vorhandene Elemente bleiben unverändert. Neue Elemente werden hinzugefügt.
Ob ein Element neu ist, entscheidet MIKE URBAN anhand der MUID. Ist die MUID laut externem Feld bereits vorhanden, wird das Element komplett ignoriert. Handelt es sich hingegen um eine neue MUID, wird das Element an die Tabelle angehängt.
Im Beispiel gibt es Überschneidungen bei den Elementen 2 und 3. Beide externen Elemente werden verworfen, nur des Element 4 wird angehängt.
Beachten Sie, dass die Attribute B und C des Elements 3 im Ausgangsdatensatz leer sind, und auch leer bleiben! ![]()

Aktualisieren
Beim Aktualisieren beschränkt sich MIKE URBAN auf Elemente mit bereits vorhandener Identifikationsbezeichnung. Bestehende Attribute werden durch neue Attribute überschrieben. Weist der Quell-Datensatz Lücken auf, wie bei den Attributen B und C des Elements 2, bleiben die bestehenden Attribute erhalten.
Element 1 bleibt unverändert erhalten, weil der Quell-Datensatz kein Element mit der gleichen ID enthält.

Hinzufügen und Aktualisieren
Anhand der MUID entscheidet MIKE URBAN, ob ein Element des Quell-Datensatzes neu ist.
Handelt es sich im ein neues Element, wird es vorhandenen der Elementliste hinzugefügt, siehe oben.
Handelt es sich um ein bestehendes Element, werden die bestehenden Attribute aktualisiert. Bestehende Attribute werden durch neue Attribute überschrieben. Weist der Import-Datensatz Lücken auf, wie bei den Attributen B und C des Elements 2, bleiben die bestehenden Attribute erhalten.
Element 1 bleibt unverändert erhalten, weil der Quell-Datensatz kein Element mit der gleichen MUID enthält.

Überschreiben
Alle bereits vorhandenen Elemente werden gelöscht. Im Bild sind daher rechts nur die neuen Elemente zu sehen. Bei einem Import in eine leere Datenbank ist dies die gängige Übertragungsart.

Sync
Es wird zuerst die Übertragungsart "Hinzufügen und Aktualisieren" durchgeführt. Danach werden alle Zieldaten gelöscht, die in den Quelldaten nicht vorhanden sind.
Filter
Filter blenden unerwünschte Zeilen aus, bevor die Zuordnungen abgearbeitet werden. Hier einige Beispiele:
Die CustomerID muss genau abc sein:
CustomerID = 'abc'
Der Layer muss in der (Liste) vorkommen. Lassen Sie keine Leerzeichen rund um die Kommas innerhalb der Liste:
Layer IN ('LEITUNG_NORD','LEITUNG_SUED')
Der Layer muss mit Leitung beginnen. Der Stern * ist eine Wildcard und steht für beliebig viele Zeichen:
Layer LIKE 'LEITUNG*'
Der Layer darf nicht HYDRANT heißen:
Layer <> 'HYDRANT'
Knoten_SW muss ein Feld ohne Eintrag sein:
Knoten_SW IS NULL
AND verbindet zwei Bedingungen durch ein logisches UND:
Verfahren IN ('Modifiziert','Trenn','Regen') AND KnotenRW IS NOT NULL
Zuweisungen
Die Zuweisungen vergeben die einzelnen Verbindungen zwischen den Attributen der Quell- und Zieltabelle. Fügen Sie eine Zuweisung hinzu, um folgende Spalten zu befüllen.
| Spaltenname | Erklärung |
|---|---|
| Ziel | Feldname des Ziels |
| Quelle | Feldname der Quelle. Über "fx" kann der Ausdruck bearbeitet werden |
| Quellbedingung | Bedingungen für die zu importierenden Datensätze. Über "?" kann der Ausdruck bearbeitet werden. |
| Einheit Quelle | Geben Sie hier die Einheit der Quelle an, damit MIKE+ diese automatisch umrechnet, wenn sie sich von der Einheit des Ziels unterscheidet. |
Beispiele für Quellbedingungen
| Ziel | Quelle | Quellbedingung |
|---|---|---|
| X | SMPRechtswert | ! IsNull ( [SMPRechtswert] ) |
Diese Zuweisung weist X den Wert von SMPRechtswert zu, sofern SMPRechtswert nicht NULL ist. Das ! steht für "nicht".
Ausdruckseditor
Dialogfeld
Tabellen verknüpfen (LookUp)
Mittels Lookup kann man Werte aus einer anderen Tabelle einlesen.
Die Lookups unterscheiden nach Datentyp. der zurückgeholt wird: Lookup_date(), Lookup_float(), Lookup_string()
Lookup_float('SuchTabelle','SuchSpalte',[Eingangswert],'RückgabeSpalte')
Mit dem [Eingangswert] wird in der 'Suchspalte' der 'Suchtabelle' nach einem passenden Wert gesucht. In der ersten Zeile mit einem Treffer wird der Wert aus der 'Rückgabespalte' gelesen und an den Lookup zurückgegeben.
Als Suchtabelle kommt sowohl eine Quelltabelle in Frage, als auch eine bereits in MIKE URBAN vorhandene Tabelle.
Das folgende Beispiel zeigt den Import von Schächten, wenn keine Schachtsohle gegeben ist. Lookup geht mit der [SchachtID] in die Tabelle 'Haltungen' und sucht in der Spalte 'Schacht_oben' nach der abgehenden Haltung. Sobald die abgehende Haltung gefunden ist, wird in der gleichen Zeile der Wert in der Spalte 'Rohrsohle oben' zurückgegeben und in beispielsweise in InvertLevel (das ist die Schachtsohle in MIKE+) geschrieben. Falls es mehrere abgehende Haltungen mit unterschiedlichen 'Rohrsohlen oben' gibt, könnte natürlich der falsche Wert erwischt werden!
Lookup_float('Haltungen','Schacht_oben',[SchachtID],'Rohrsohle_oben')